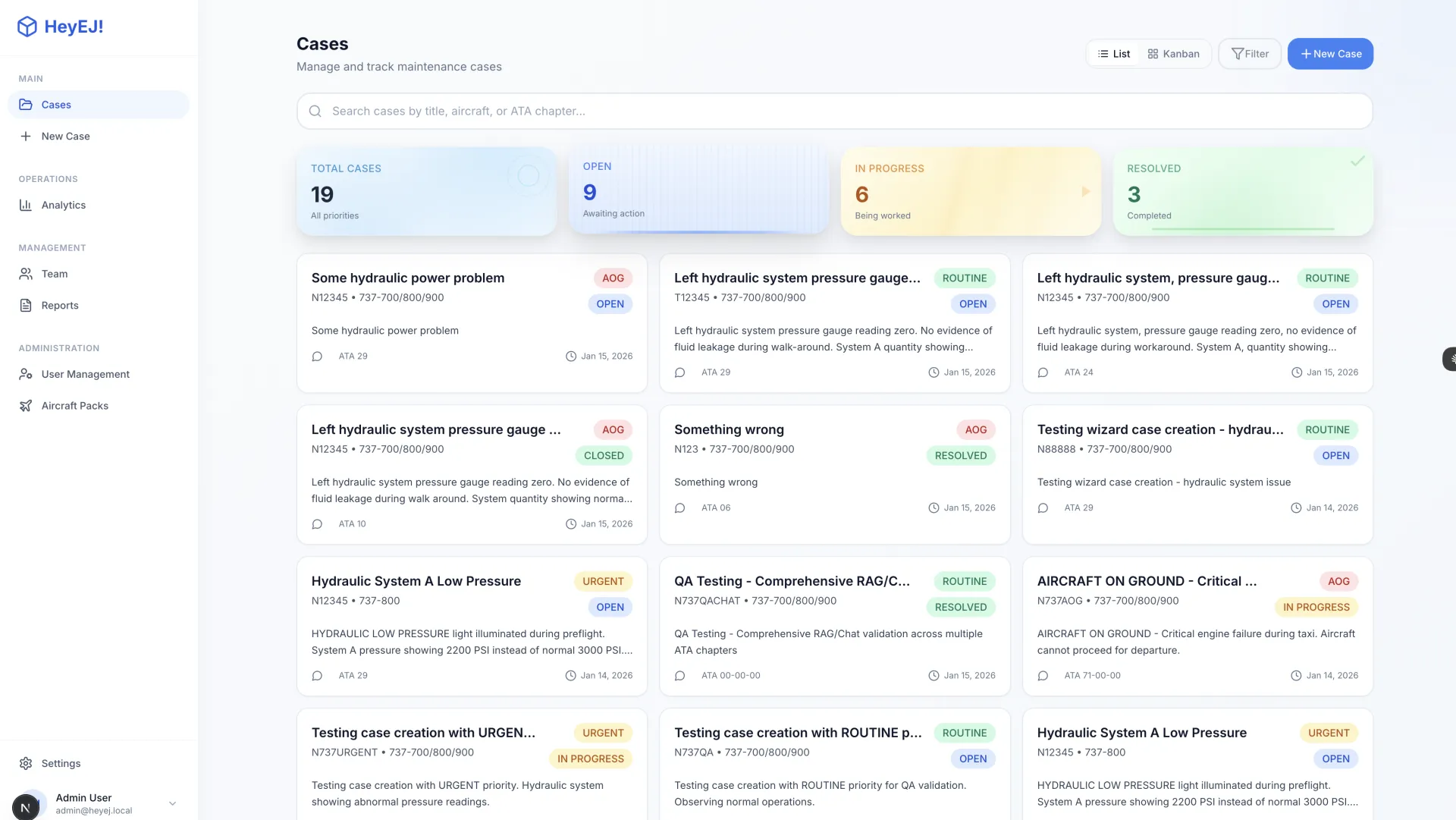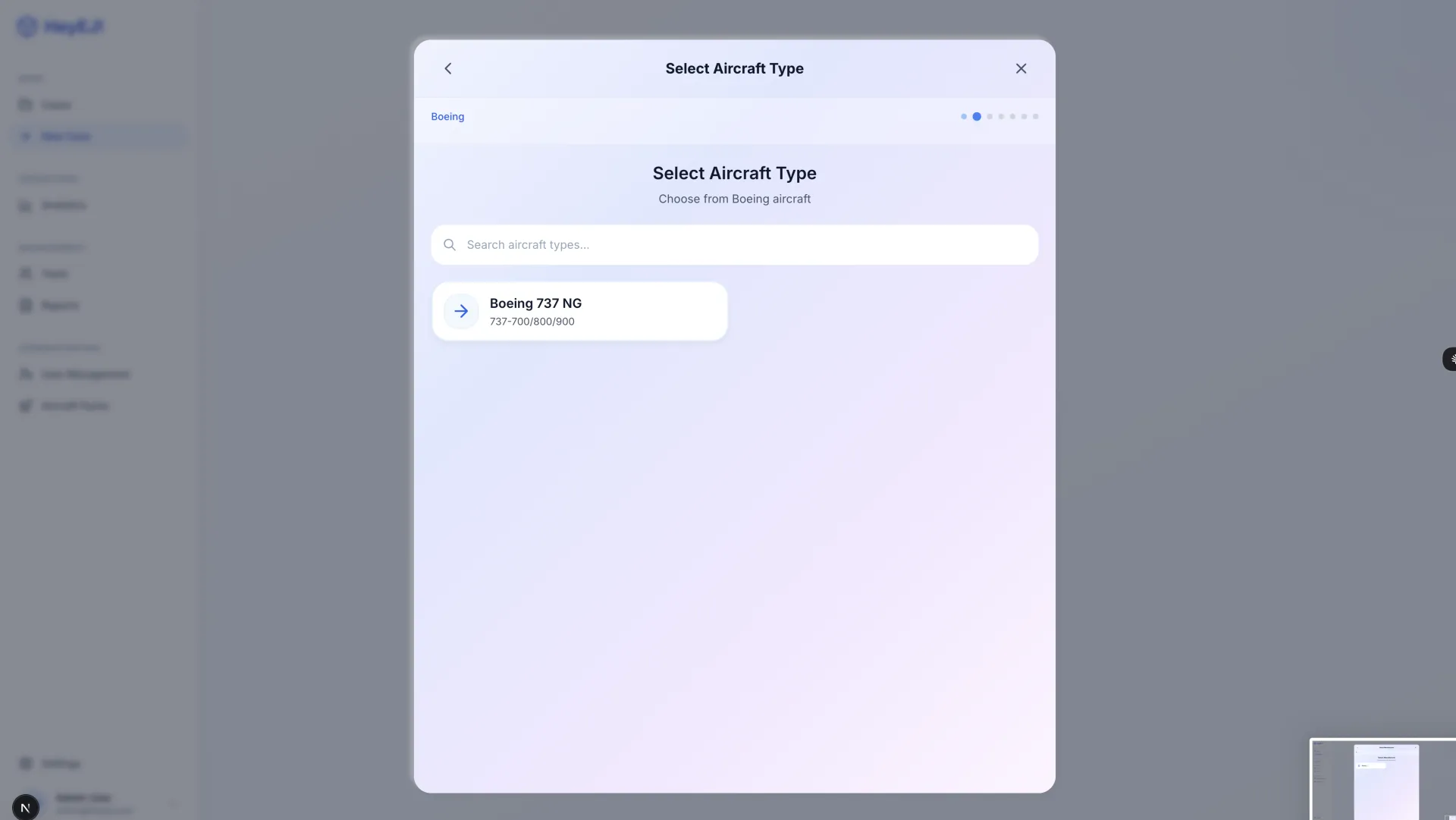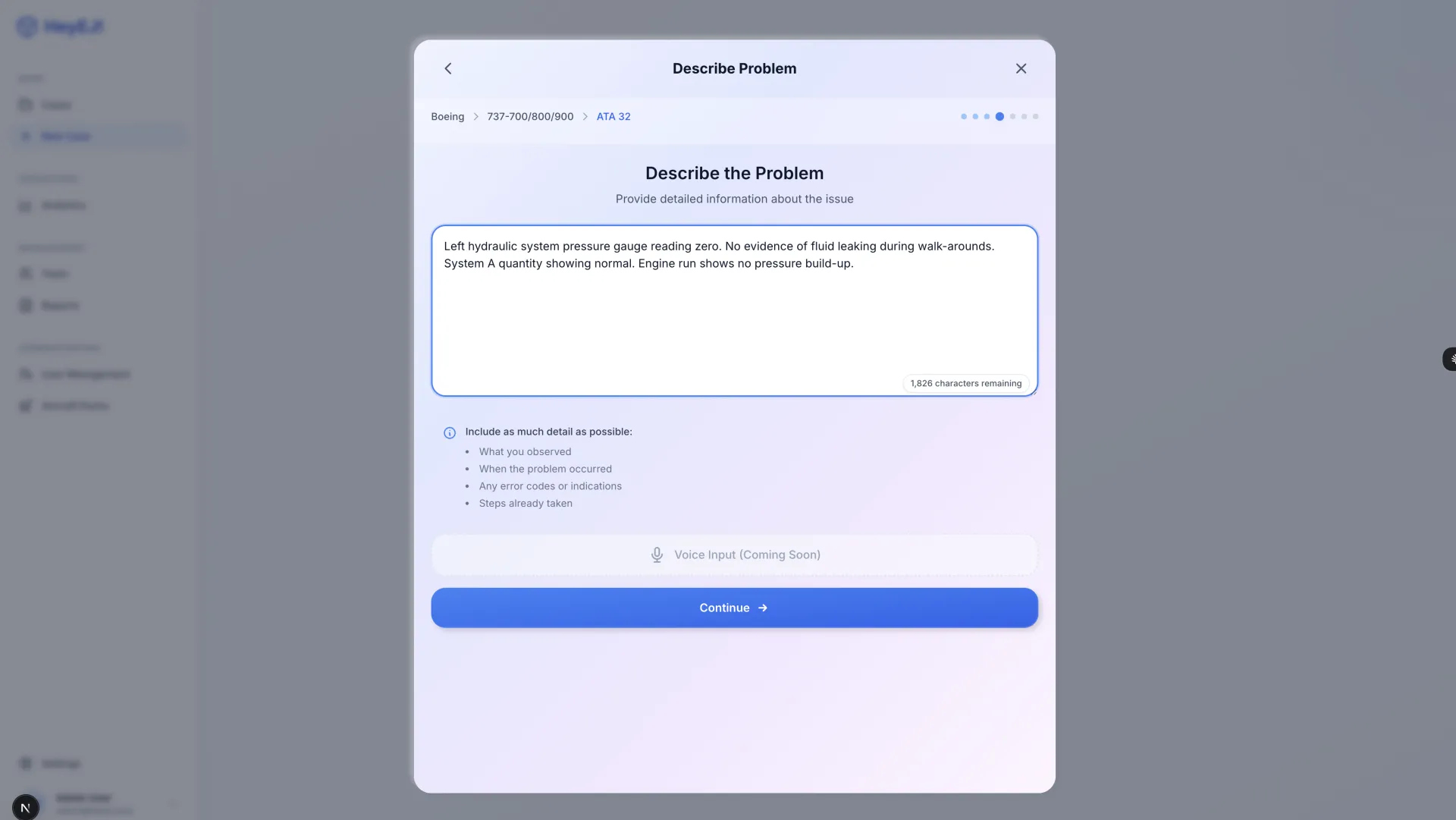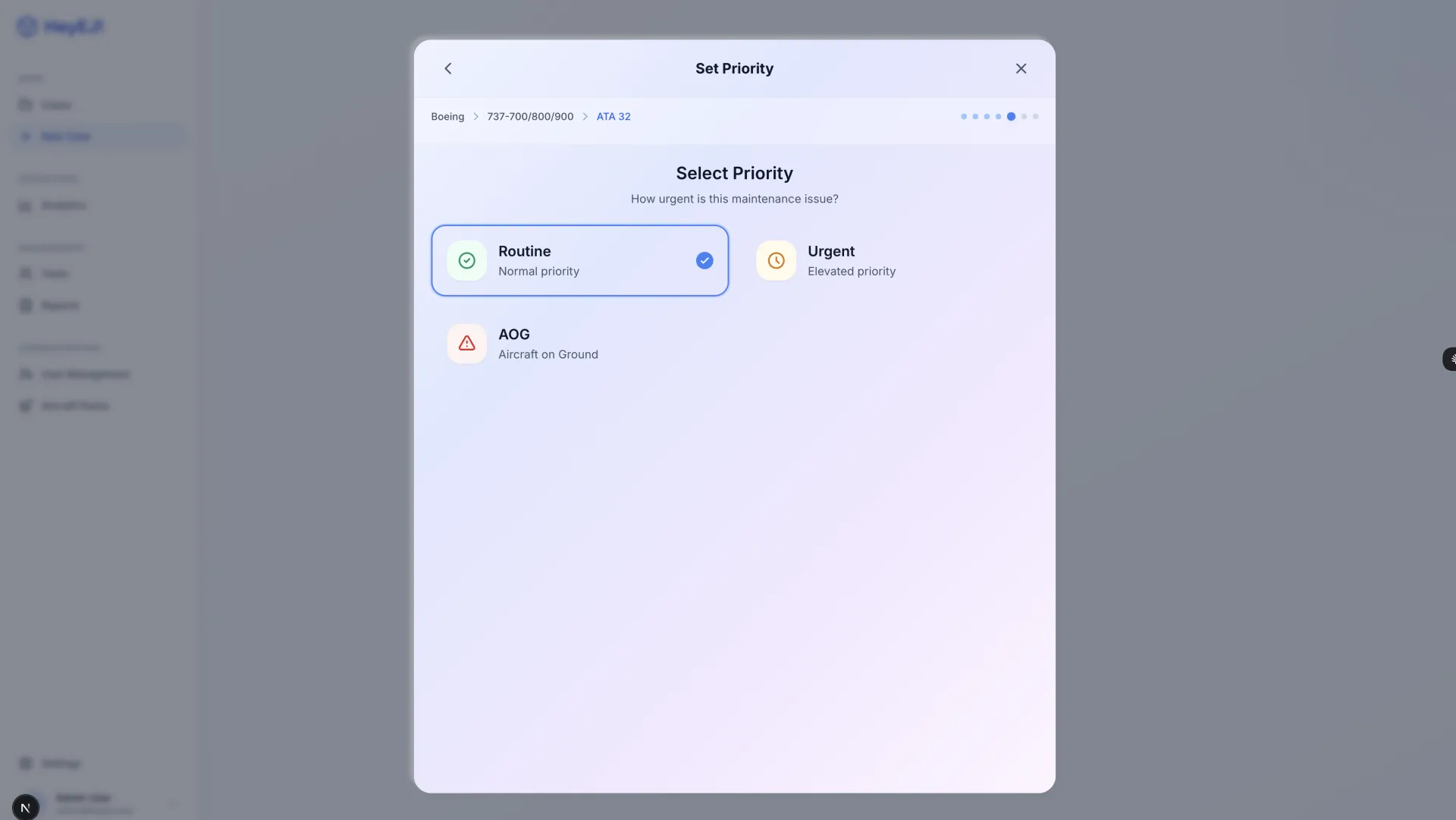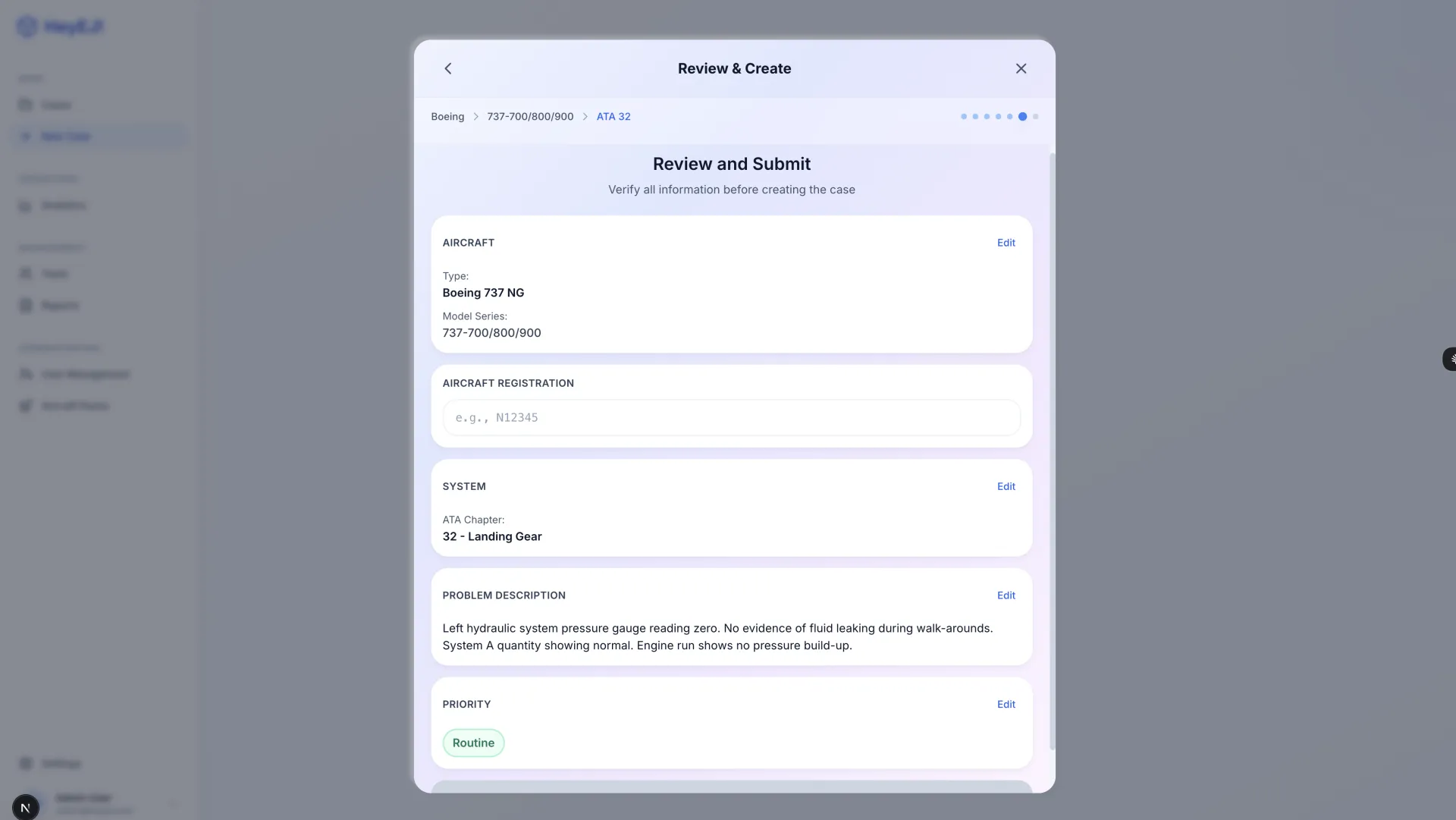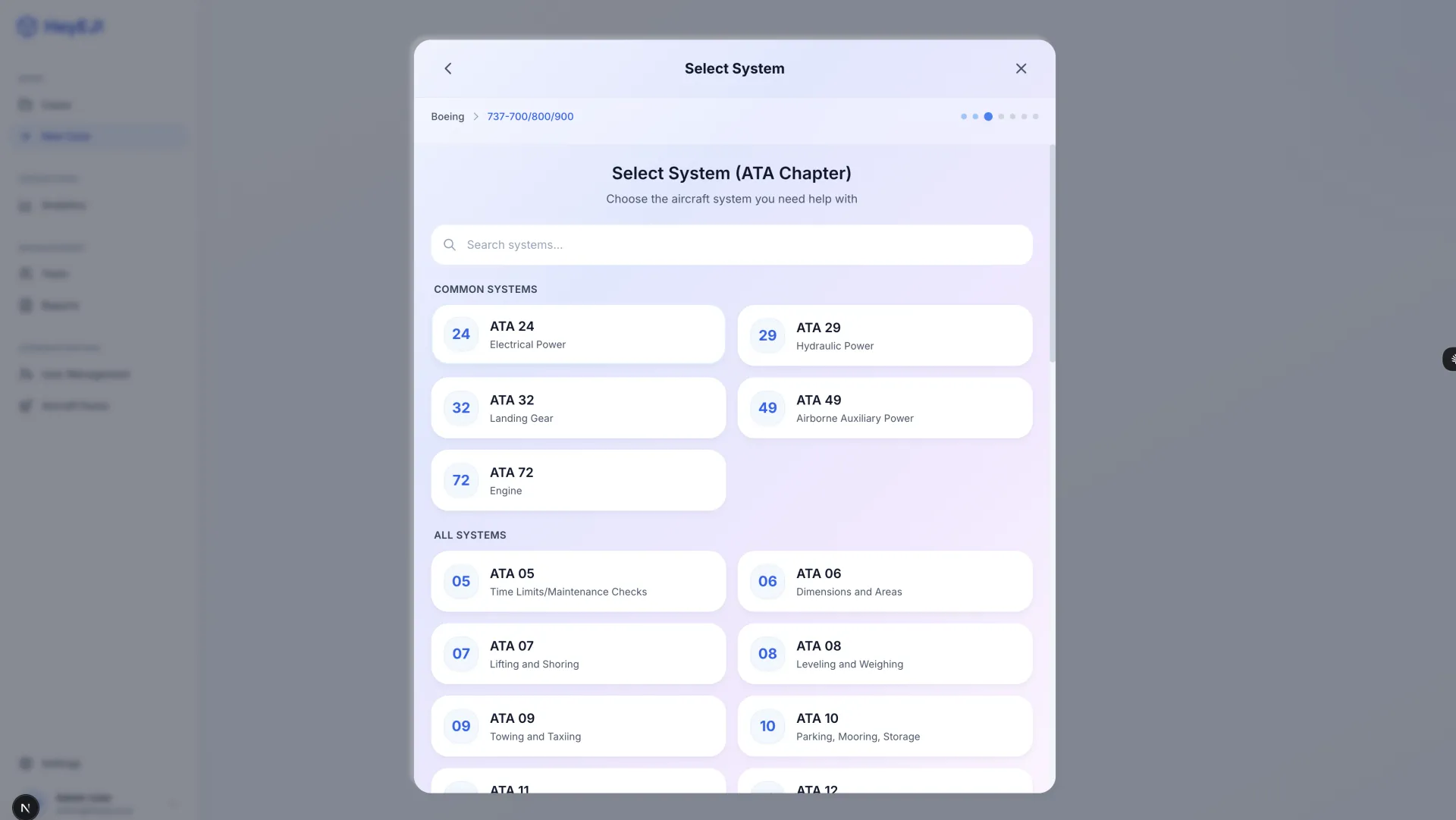
HeyEJ is a working prototype of an AI-assisted aircraft maintenance diagnostic platform built on retrieval-augmented generation (RAG). The goal: give technicians answers grounded in actual manufacturer maintenance manuals — not general AI knowledge that can hallucinate part numbers, procedures, or torque specifications — with every diagnostic response carrying a mandatory citation back to its source.
OneChair built the full platform — RAG pipeline, multi-tenant data model, asynchronous manual ingestion path, multi-turn diagnostic workflow, and admin controls — in approximately five hours. A traditional AI development agency would scope a comparable build at 3 to 4 months of senior engineering work. The engagement didn't proceed to full production due to client-side financial constraints, and no manufacturer manuals were ingested into the working system. What the build demonstrates is range: that a complete safety-critical AI architecture can be stood up in a single working day.
- ~5 hours total build time for a working RAG-powered prototype
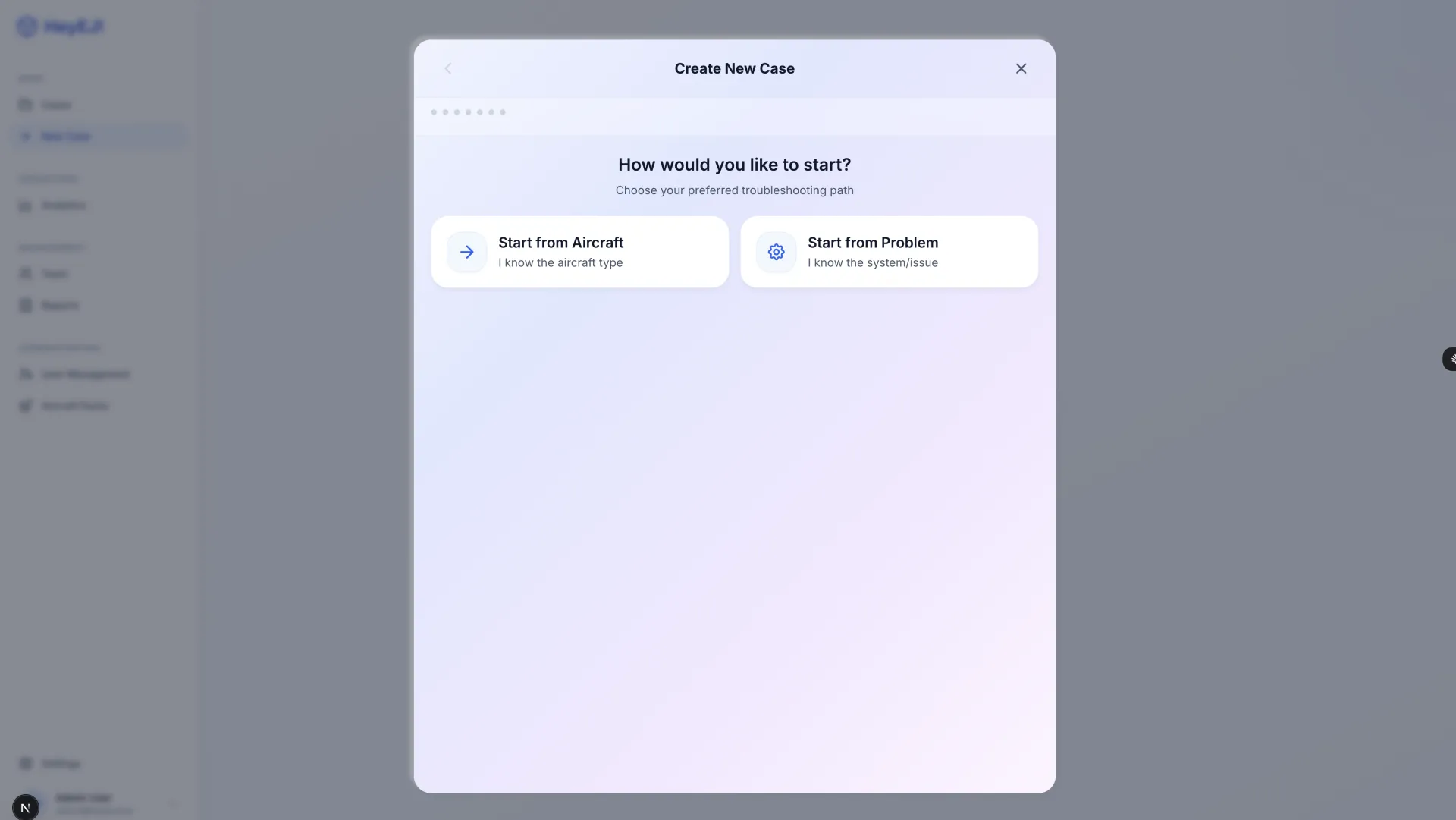
- 11 screens delivered: full diagnostic workflow, case management, user administration, aircraft configuration
- Mandatory citation architecture — every AI response structurally required to cite source manual content
- Multi-tenant architecture built into the data model from day one
- pgvector semantic search pipeline standing up over a working ingestion path
- Architectural pattern for safety-critical AI, demonstrated end-to-end in a single working session